
Google представила EmbeddingGemma — модель, яка поєднує компактність і високу продуктивність. Вона створена для локальної роботи на пристроях і відкриває нові можливості у сфері генерації ембеддингів.
🔑 Ключові особливості EmbeddingGemma
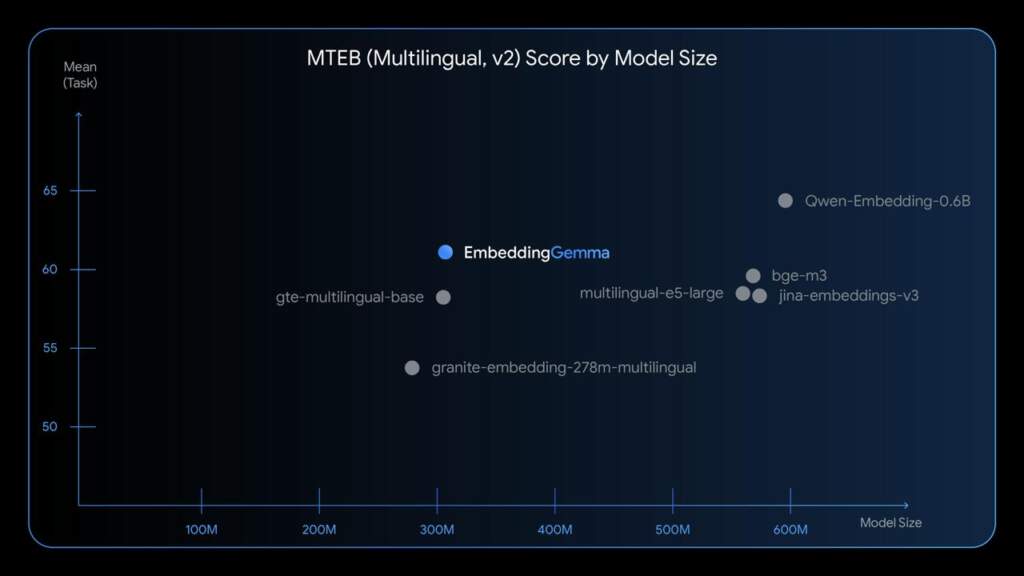
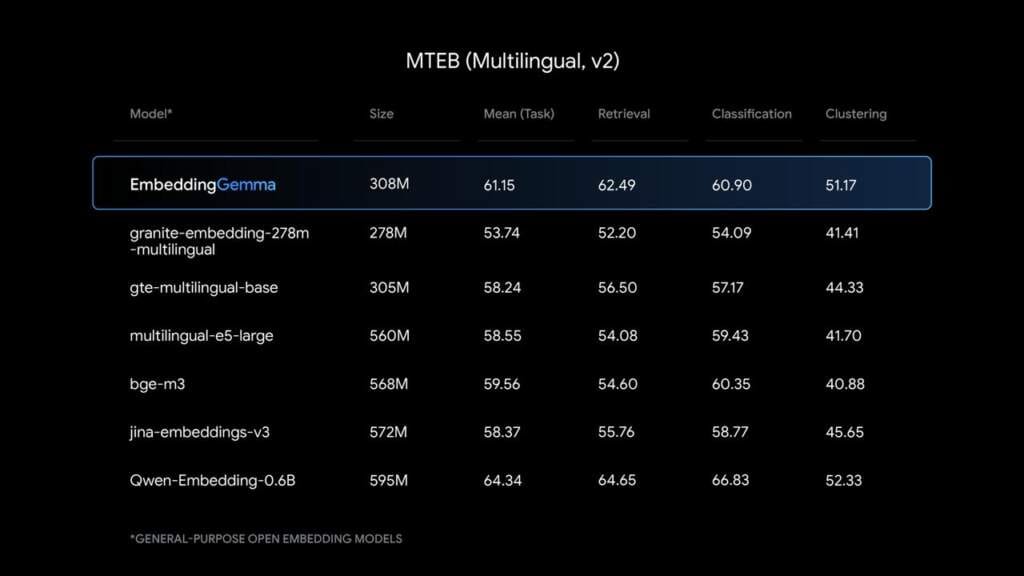
- Компактна, але ефективна: 308 млн параметрів, які за продуктивністю порівнянні з більшими моделями.
- Багатомовність: підтримка понад 100 мов, включаючи малопоширені.
- Приватність: робота без інтернету прямо на пристрої.
- Мінімальне споживання пам’яті: менше ніж 200 МБ після квантизації.
- Швидкість: обчислення ембеддингу (256 токенів) займає <15 мс на EdgeTPU.
- Гнучка розмірність: вибір векторів 128–768 завдяки Matryoshka Representation Learning.
- Широкі інтеграції: сумісність із sentence-transformers, llama.cpp, MLX, Ollama, LMStudio, LiteRT, Cloudflare, LlamaIndex та LangChain.
📌 Додаткові подробиці
- Архітектура: на основі Gemma 3 з енкодером і mean pooling.
- Дані для навчання: ≈320 млрд токенів (тексти, код, документи, синтетичні дані).
- Контекстне вікно: до 2048 токенів.
- Рейтинг у MTEB: найкраща серед моделей до 500 М параметрів.
- Хмарна масштабованість: інтеграція з Google Cloud Dataflow та AlloyDB.
⚙️ Де застосовується EmbeddingGemma
- Приватні RAG-асистенти та чатботи.
- Семантичний пошук і рекомендаційні системи.
- Класифікація та кластеризація даних.
- Інтеграція в пайплайни Google Cloud.
- Тонке донавчання для спеціалізованих задач (наприклад, у медицині).
💻 Приклад інтеграції
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("google/embeddinggemma-300m")
emb = model.encode(["Ваш текст"])
EmbeddingGemma — це потужний інструмент, що поєднує швидкість, багатомовність і безпеку. Його можна використовувати як на мобільних пристроях, так і у великих хмарних проєктах. Google зробила ставку на on-device AI, і це може стати новим стандартом у роботі з ембеддингами.









