
У лютому 2026 року компанія Google DeepMind представила результати тестування своєї нової моделі — Gemini 3.1 Pro. Ця версія демонструє суттєвий прогрес у складних завданнях, що потребують глибокого аналізу, мультимодального сприйняття та роботи в автономному режимі (agentic capabilities).
Методологія тестування
Оцінка проводилася за принципом pass @1 — це означає, що модель мала лише одну спробу для надання правильної відповіді, без можливості паралельних обчислень або голосування за більшістю результатів. Для тестів використовувався API ідентифікатор gemini-3.1-pro-preview із налаштуваннями семплювання за замовчуванням.
Ключові досягнення та результати
1. Логіка та наукові знання
Gemini 3.1 Pro показала вражаючі результати в академічних та логічних тестах:
- Humanity’s Last Exam: Модель досягла показника 44.4%, значно випередивши попередню версію Gemini 3 Pro (37.5%) та конкурентів, таких як GPT-5.2 (34.5%).
- GPQA Diamond: У тестах на глибокі наукові знання точність склала 94.3%.
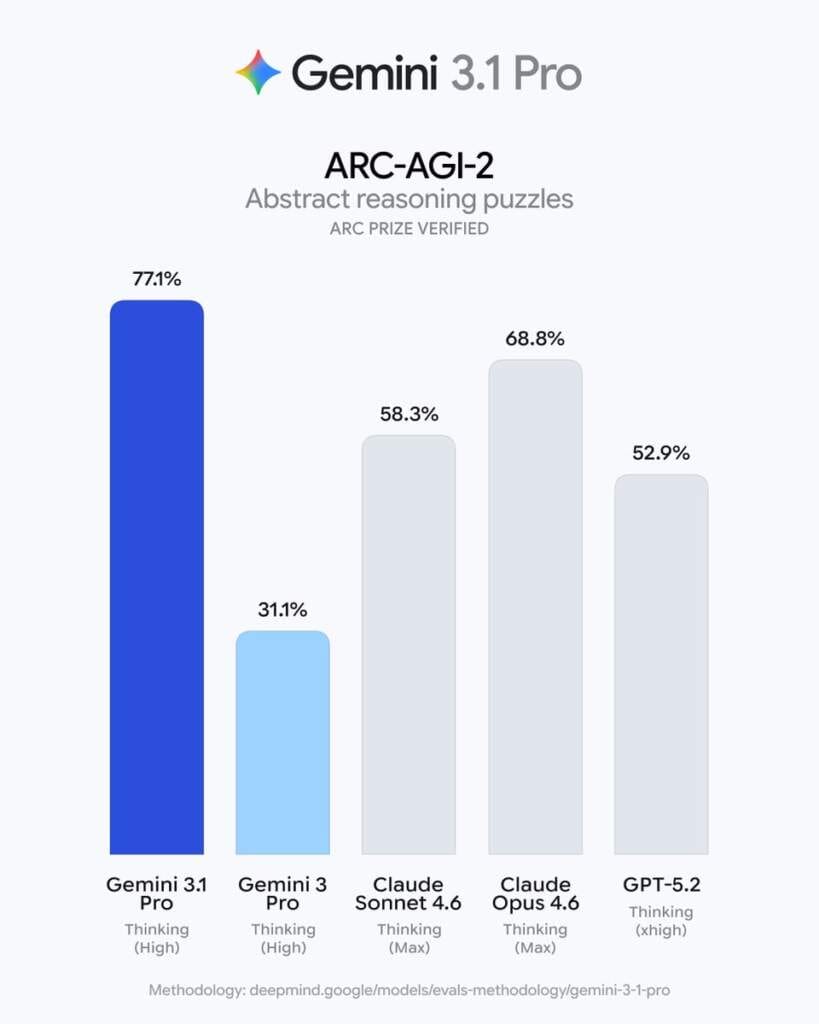
- ARC-AGI-2: В іспиті на абстрактне мислення модель отримала 77.1%, що є одним із найвищих показників у галузі.
2. Програмування та автономні агенти
Особливу увагу приділено здатності моделі працювати як автономний агент:
- SWE-Bench Verified: У завданнях з виправлення реальних помилок у програмному коді модель досягла успіху у 80.6% випадків. Під час тестування команда Google навіть виявила та виправила помилки в самому тестовому середовищі (наприклад, у бібліотеці astropy), що дозволило моделі показати ще точніші результати.
- Terminal-Bench 2.0: У роботі з терміналом та командним рядком Gemini 3.1 Pro набрала 68.5%.
- LiveCodeBench Pro: В умовах змагального програмування (Codeforces, ICPC) модель отримала Elo-рейтинг 2887.
3. Робота з довгим контекстом та мультимодальність
Gemini 3.1 Pro продовжує лідирувати в обробці великих обсягів даних:
- Контекст: Модель підтримує вікно контексту до 1 мільйона токенів. У тестах MRCR v2 на пошук інформації (“голка в стозі сіна”) середня точність на 128k токенів склала 84.9%.
- Мультимодальність: У тесті MMMLU (багатомовне розуміння) результат сягнув 92.6%, що підтверджує високу ефективність моделі на різних мовах.
- MMMU Pro: Візуальне розуміння та логіка оцінені у 80.5%.
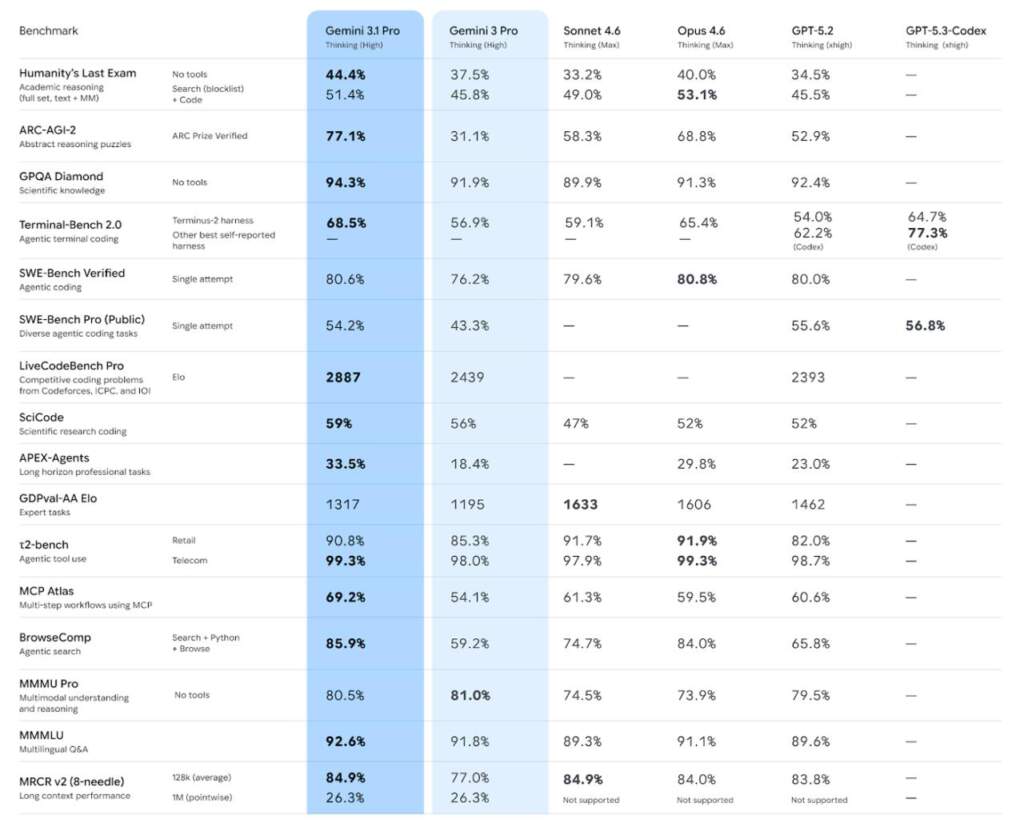
Порівняльна таблиця (вибрані показники)
| Бенчмарк | Gemini 3.1 Pro | Gemini 3 Pro | GPT-5.2 | Sonnet 4.6 |
| GPQA Diamond (Наука) | 94.3% | 91.9% | 92.4% | 89.9% |
| SWE-Bench Verified (Код) | 80.6% | 76.2% | 80.0% | 79.6% |
| ARC-AGI-2 (Логіка) | 77.1% | 31.1% | 52.9% | 58.3% |
| MMMLU (Мультимовність) | 92.6% | 91.8% | 89.6% | 89.3% |
Gemini 3.1 Pro демонструє якісний стрибок у здатності ШІ діяти автономно, розв’язувати складні наукові задачі та ефективно працювати з величезними масивами інформації. Це робить її однією з найпотужніших моделей для професійного використання на початку 2026 року.
Вже можна безкоштовно тестувати в AI Studio.









