
Сьогодні OpenAI представили новий бенчмарк SWE-Lancer, призначений для оцінювання можливостей передових мовних моделей (LLM) у виконанні реальних фріланс-завдань із програмування. Бенчмарк охоплює 1488 (гусари, мовчати) завдань із платформи Upwork, сумарною вартістю $1 млн, і охоплює як індивідуальні інженерні завдання, так і управлінські (що особливо цікаво, тобто оцінюються не тільки навички програмування, а й менеджерські).
Розробники оцінювали моделі у двох категоріях: IC SWE, де AI розв’язує інженерні задачі, і SWE Manager, де AI обирає найкращу технічну пропозицію з-поміж кількох. Для перевірки результатів використовувалися end-to-end тести, створені та тричі перевірені професійними розробниками.
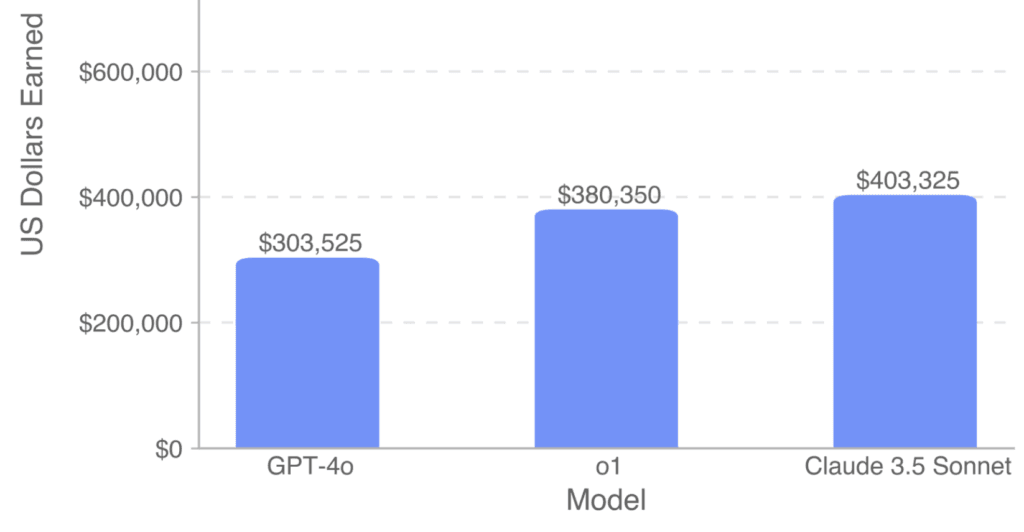
Випробування показали, що сучасні моделі поки що не здатні виконувати більшість завдань. Найкраща з протестованих, Claude 3.5 Sonnet, змогла заробити $208 050 на підмножині завдань вартістю $500 800, але її успіхи залишаються обмеженими.

Розробники оцінювали моделі у двох категоріях: IC SWE, де AI розв’язує інженерні задачі, і SWE Manager, де AI обирає найкращу технічну пропозицію з-поміж кількох. Для перевірки результатів використовувалися end-to-end тести, створені та тричі перевірені професійними розробниками.
Випробування показали, що сучасні моделі поки що не здатні виконувати більшість завдань. Найкраща з протестованих, Claude 3.5 Sonnet, змогла заробити $208 050 на підмножині завдань вартістю $500 800, але її успіхи залишаються обмеженими.

Дослідники вважають, що SWE-Lancer дасть змогу глибше вивчити економічний вплив AI у сфері програмування, а також визначити його потенціал як фріланс-інструменту. Дані бенчмарка частково відкриті для досліджень, повний доступ надається за запитом.
OpenAI підкреслили, що SWE-Lancer також допоможе розробникам оцінити безпеку автономних AI-агентів у програмуванні та виявити ризики автоматизації складних інженерних процесів.









