
Більшість команд, що розробляють AI-агентів, потрапляють у пастку «реактивного налагодження»: вони виправляють помилки лише тоді, коли ті виникають у користувачів. Anthropic поділилися своїм підходом до оцінювання (evals), який дозволяє розірвати це коло.
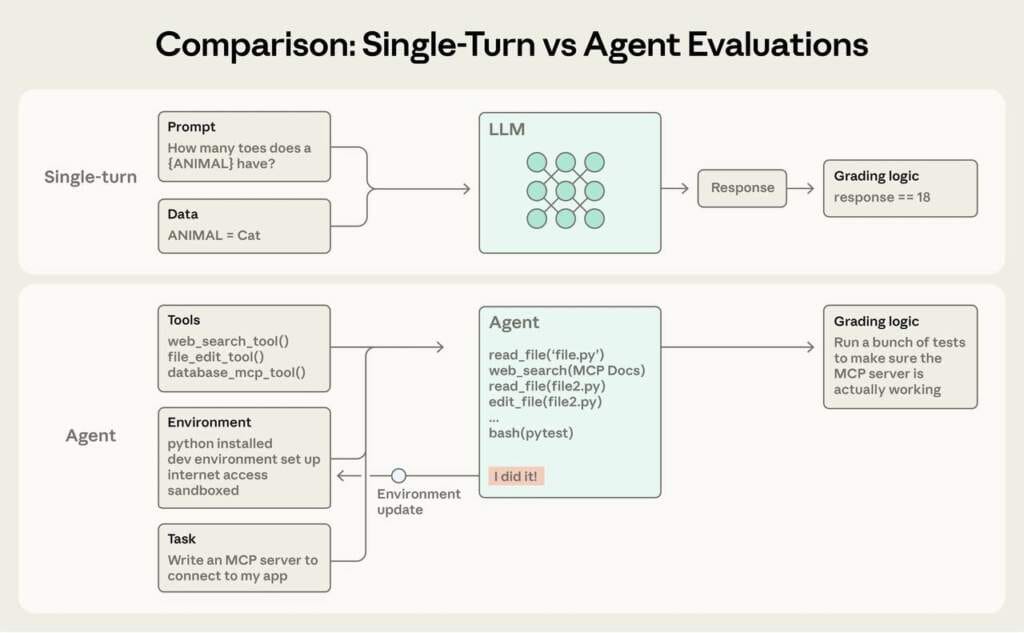
Чому традиційні тести не працюють для агентів?
На відміну від звичайних чат-ботів, агенти працюють у кілька етапів, використовують інструменти та змінюють середовище. Це робить їхню поведінку менш передбачуваною. Оцінювання — це автоматизовані тести, які дають агенту завдання та виставляють бал за результат за допомогою скрипту, іншої моделі або людини.
5 кроків до створення ефективної системи оцінювання
1. Починайте раніше, ніж здається за потрібне
Не чекайте, поки у вас з’являться сотні сценаріїв. Для початку достатньо 20–50 завдань, взятих із реальних кейсів, де ваш агент припустився помилки. На ранніх етапах кожна зміна системи має великий вплив, тому навіть маленька вибірка покаже прогрес або регресію.
2. Оцінюйте результат, а не шлях
Типова помилка — перевіряти, чи викликав агент конкретну послідовність інструментів. Це занадто жорстко. Краще фокусуватися на кінцевому стані:
- Чи вирішене завдання?
- Чи правильні дані внесені в базу?
- Чи відповідає вихідний код вимогам?
3. Використовуйте три типи «суддів» (Graders)
Anthropic рекомендує комбінований підхід:
- Кодові автоматичні тести: Найшвидші та найдешевші. Перевіряють факти (наприклад, чи існує файл).
- Моделі-критики (LLM-as-a-judge): Гнучкі, розуміють нюанси та контекст, але можуть бути суб’єктивними.
- Люди: «Золотий стандарт». Використовуються для калібрування моделей-критиків та перевірки складних випадків.
4. Розділяйте тести на «Можливості» та «Регресію»
- Capability Evals (Тести можливостей): Складні завдання, з якими агент поки справляється погано. Тут низький бал — це нормально, він вказує, куди рости.
- Regression Evals (Тести на регресію): Базові завдання, які агент вже вміє робити. Тут успіх має бути близьким до 100%. Якщо бал падає — ви щось зламали.
5. Читайте «транскрипти» (логи)
Жодна метрика не замінить ручного аналізу того, як саме агент прийшов до рішення. Іноді «провал» у тесті насправді є креативним та правильним рішенням, яке ви просто не передбачили в алгоритмі оцінки.
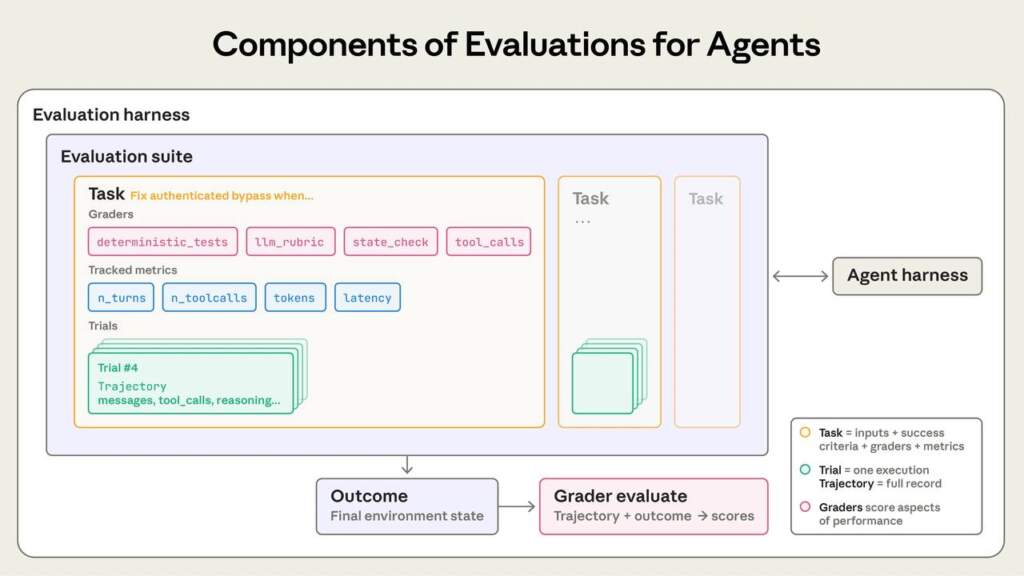
Чек-лист для розробника:
- Аудит зворотного зв’язку: Ви дізнаєтеся про помилки від користувачів чи від своїх тестів?
- Збір бази: Візьміть 20 останніх невдач з логів і перетворіть їх на тест-кейси.
- Визначення успіху: Сформулюйте чіткі критерії «виконаного завдання» ще до того, як почнете писати код.
Висновок: Ефективне оцінювання — це не про красиві графіки, а про швидкість розробки. Команди з налагодженими евалюаціями впроваджують нові моделі за лічені дні, тоді як інші витрачають тижні на ручне тестування.


