
Google DeepMind опублікувала офіційний гайд зі створення ефективних запитів для Gemini Omni — нової мультимодальної AI-моделі, яка може працювати одночасно з текстом, відео, зображеннями та аудіо. Документ вже викликав значний інтерес серед творців контенту, маркетологів та розробників, адже розкриває принципи роботи одного з найамбітніших проєктів компанії.
На відміну від традиційних генераторів контенту, Gemini Omni орієнтується не лише на виконання текстових команд. Модель використовує знання про реальний світ, аналізує контекст і здатна створювати складні відеосцени за допомогою природної мови. Саме тому Google рекомендує змінити підхід до створення промптів і зосередитися не на дрібних деталях, а на творчому керуванні процесом.
Як працює Gemini Omni
Gemini Omni стала першим представником нової лінійки моделей Omni від Google DeepMind. Головна особливість технології полягає у можливості створювати контент з будь-яких типів вхідних даних.
Користувач може завантажити текст, фотографію, аудіозапис або відео, після чого модель згенерує новий матеріал або відредагує вже існуючий. У Google називають це концепцією «create anything from anything» — створення будь-чого з будь-якого контенту.
Особливий акцент зроблено на відеогенерації. Модель може підтримувати сталість персонажів, зберігати логіку сцен та коректно обробляти складні переходи між кадрами навіть після кількох раундів редагування.
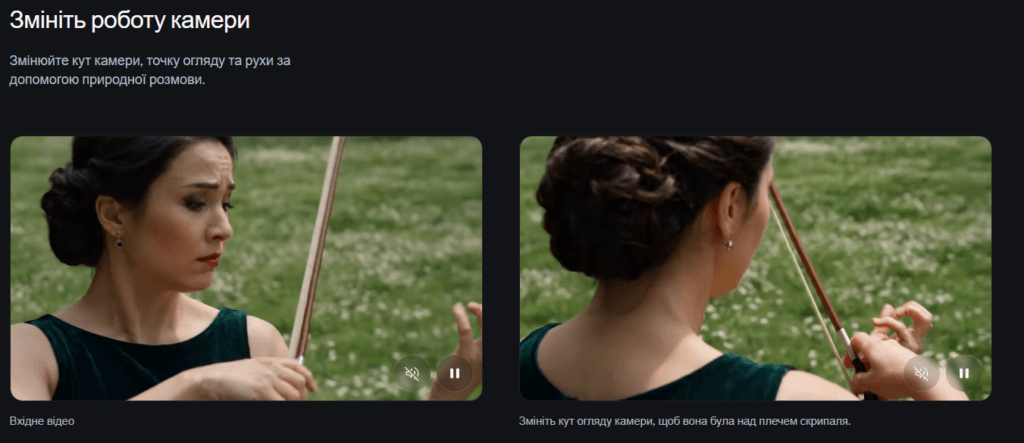
Що радить офіційний гайд
У новому Prompt Guide команда DeepMind пояснює, що ефективний промпт для Gemini Omni більше нагадує режисерське завдання, ніж технічну інструкцію.
Наприклад, користувачам рекомендують прямо вказувати тип камери, стиль зйомки та рухи об’єктива. Можна використовувати такі команди як «one continuous shot» для безперервного кадру, «dolly zoom» для кінематографічного ефекту або «smartphone camera style» для імітації зйомки на телефон.
Також Google радить:
- описувати бажану атмосферу сцени;
- задавати рух камери;
- вказувати тип освітлення;
- використовувати референси до жанрів та стилів;
- залишати простір для інтерпретації моделі.
Фахівці компанії наголошують, що надмірна деталізація може навіть погіршити результат. Завдяки вбудованим знанням про світ Gemini Omni здатна самостійно доповнювати сцену логічними деталями.
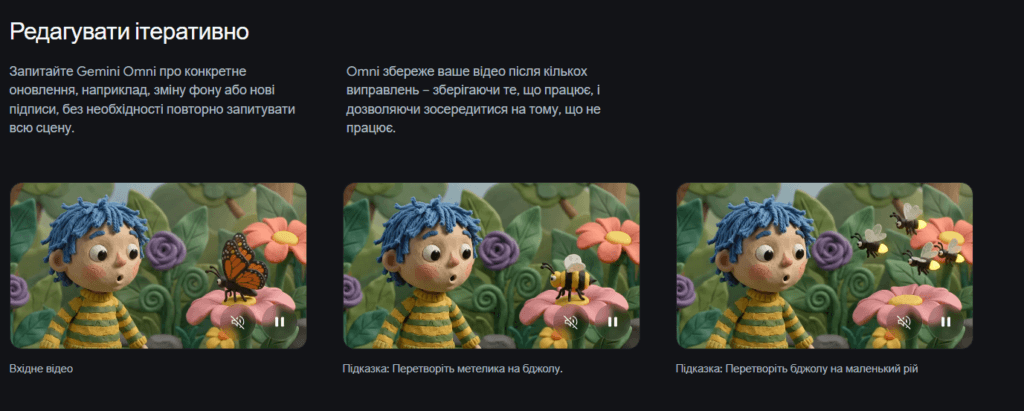
Новий підхід до промпт-інжинірингу
Поява Gemini Omni демонструє зміну всієї індустрії генеративного AI.
Якщо раніше користувачам доводилося прописувати десятки технічних параметрів, то нові моделі все більше покладаються на власне розуміння контексту. Експерти відзначають, що майбутнє промпт-інжинірингу полягає не в написанні довгих інструкцій, а в правильній постановці творчого завдання.
Крім того, Google активно просуває концепцію мультимодальної взаємодії. Це означає, що користувач може вести діалог з моделлю, поступово уточнюючи результат замість створення нового запиту з нуля.
Чому це важливо
Gemini Omni може суттєво змінити ринок створення контенту.
Для блогерів і YouTube-авторів це шанс швидше виробляти відео та анімації. Для маркетологів — можливість створювати рекламні ролики без великих продакшн-команд. Для бізнесу — автоматизувати виробництво мультимедійного контенту та скоротити витрати.
Також запуск офіційного гайду показує, що Google серйозно готується до конкуренції з OpenAI, Runway та іншими розробниками AI-генераторів відео. Компанія прагне зробити створення професійного контенту доступним для ширшої аудиторії.
Офіційний Prompt Guide для Gemini Omni став важливим кроком у розвитку мультимодального штучного інтелекту. Google фактично пропонує новий стандарт взаємодії з AI-системами, де користувач виступає не програмістом, а режисером творчого процесу.
Завдяки підтримці тексту, відео, зображень та аудіо Gemini Omni може стати одним із ключових інструментів для створення контенту нового покоління. А рекомендації DeepMind вже зараз допомагають зрозуміти, як отримувати максимально якісний результат від сучасних AI-моделей.
Детальні рекомендації щодо створення ефективних промптів доступні в офіційному гайді Google DeepMind: Gemini Omni Prompt Guide
❓ Поширені питання про Gemini Omni
Що таке Gemini Omni?
Gemini Omni — це ключова тема, технологія або інструмент у сфері штучного інтелекту, що детально розглядається та аналізується у цій статті на нашому ресурсі.
Як працює Gemini Omni?
Gemini Omni функціонує на основі передових нейромережевих архітектур і алгоритмів машинного навчання, що дозволяє досягати максимальної точності та ефективності в роботі.
Де використовується Gemini Omni?
Gemini Omni знаходить широке застосування в автоматизації рутинних завдань, генерації контенту, аналітиці даних та розробці сучасних програмних рішень.


