
OpenAI оголосила про випуск GPT-5.2, позиціонуючи його як найдосконалішу серію моделей на сьогодні, спеціально розроблену для складної професійної інтелектуальної роботи та складних автономних агентських систем. Цей реліз містить значні покращення в усіх ключових сферах — від кодування та візуального сприйняття до обробки надвеликих контекстів, що обіцяє значну економічну вигоду для користувачів.
Виняткова продуктивність у професійних завданнях
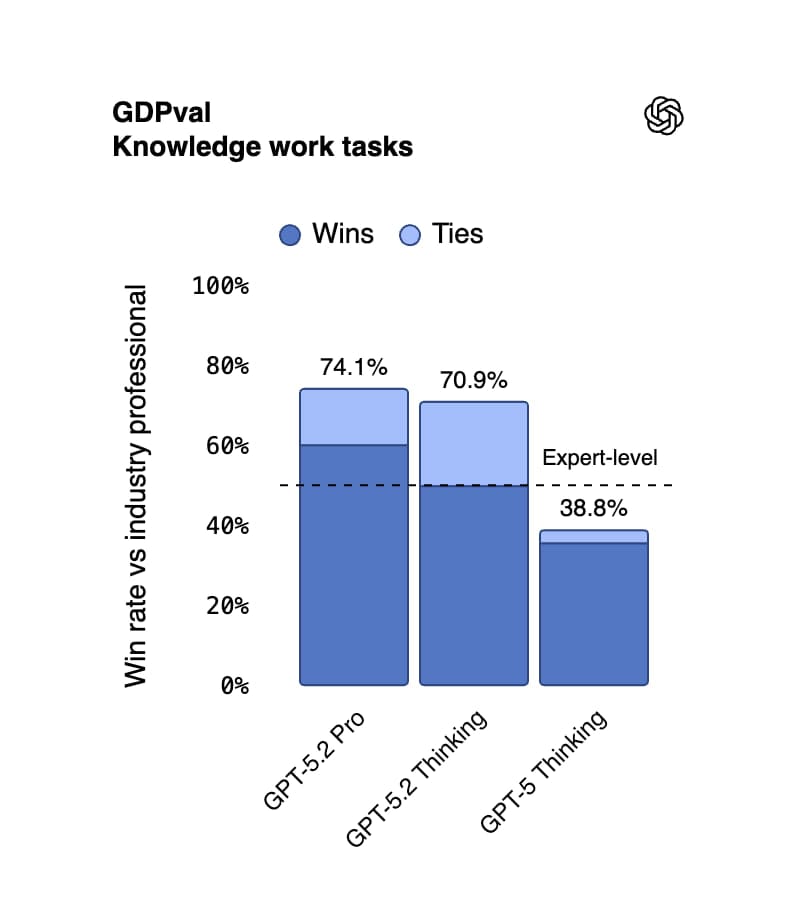
GPT-5.2 Thinking демонструє значно вищу ефективність у економічно цінних завданнях. На бенчмарку GDPval, який оцінює роботу зі знаннями у 44 професіях (включаючи створення презентацій та електронних таблиць), модель перемагає або зрівнюється з професіоналами галузі у 70,9% випадків. Це колосальний стрибок порівняно з 38,8% у GPT-5. Крім того, модель виконує ці завдання у 11 разів швидше і коштує менше 1% від ціни роботи експерта.
Новий рівень у кодуванні
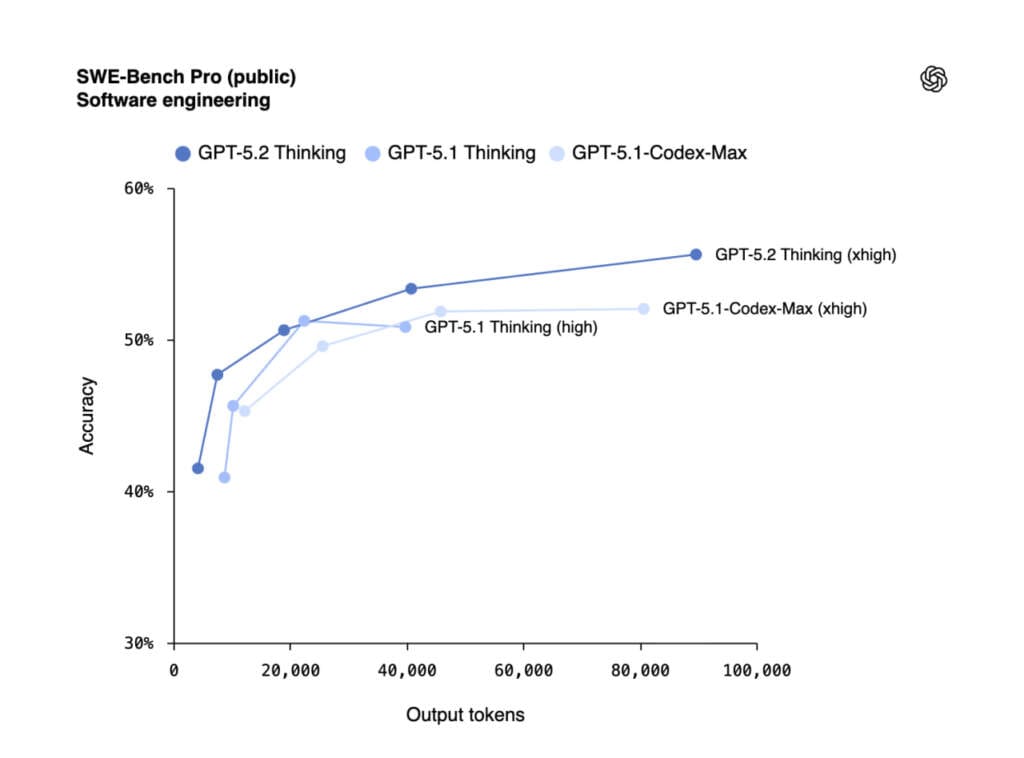
Для розробки програмного забезпечення GPT-5.2 встановлює новий рекорд, набравши 55,6% на складному оцінюванні SWE-Bench Pro. Це свідчить про розширені можливості моделі в:
- Надійному налагодженні виробничого коду.
- Рефакторингу великих кодових баз.
- Розробці інтерфейсів (front-end), включаючи складні та нетрадиційні елементи, зокрема 3D.
Підвищена надійність та точність
Модель стала значно надійнішою. Рівень помилок/галюцинацій у відповідях на запити ChatGPT знизився на 30% порівняно з GPT-5.1, що робить її більш достовірним інструментом для досліджень, аналізу та прийняття рішень.
Майстерність у роботі з великим контекстом
GPT-5.2 Thinking досягає фактично бездоганної точності (близько 100%) на варіанті MRCRv2 з 4 «голками» при роботі з контекстом до 256 000 токенів. На практиці це дозволяє професіоналам використовувати модель для глибокого аналізу та синтезу інформації з величезних документів, контрактів, наукових робіт або багатофайлових проєктів.
Покращені здібності до візуального сприйняття
Можливості бачення GPT-5.2 Thinking покращилися настільки, що частота помилок зменшилася приблизно вдвічі у таких сферах, як інтерпретація графіків та розуміння інтерфейсів програмного забезпечення (бенчмарк ScreenSpot-Pro, 86,3% точності). Модель демонструє значно краще просторове розуміння розташування елементів зображення.
Надійна робота з інструментами та агентами
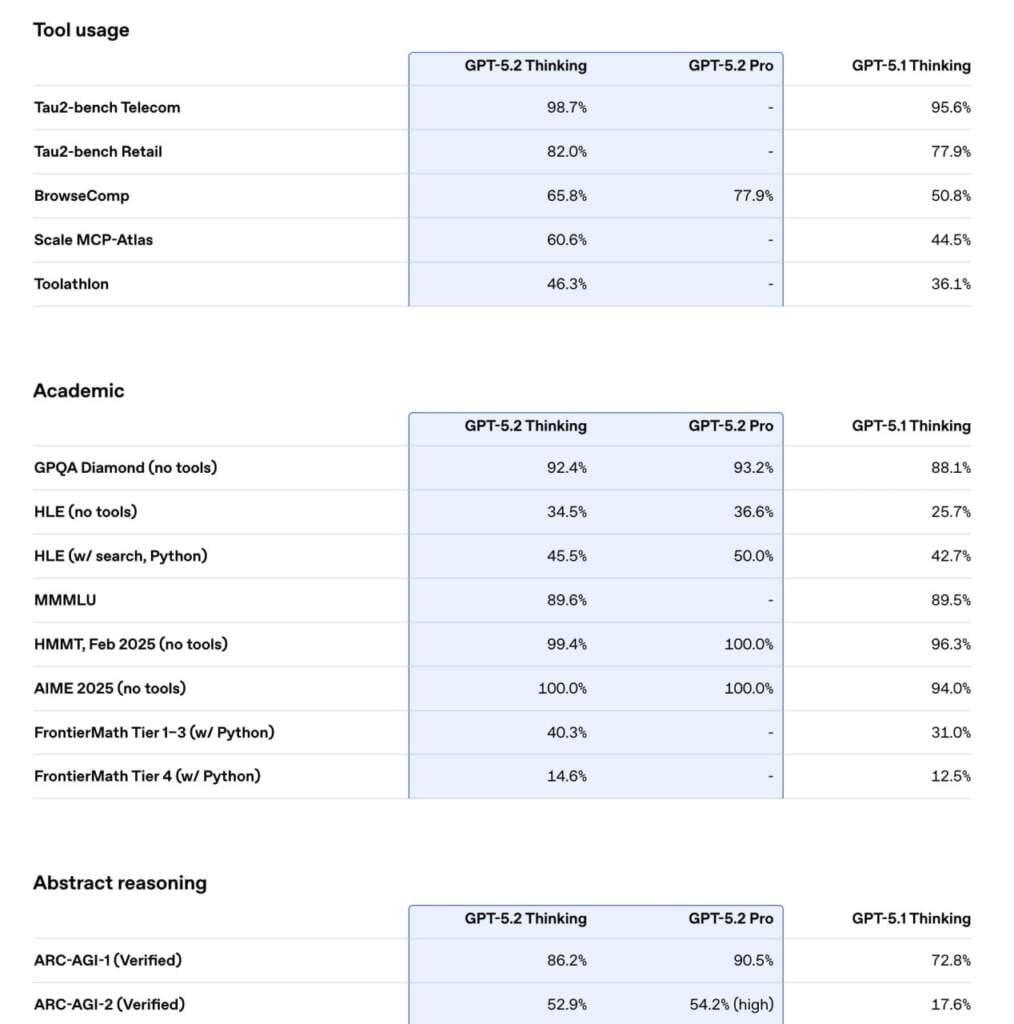
З показником 98,7% на бенчмарку Tau2-bench Telecom, GPT-5.2 Thinking встановлює новий стандарт у здатності надійно використовувати інструменти. Це забезпечує надійніші наскрізні багатоетапні робочі процеси, наприклад, повне розв’язання складних багатокрокових запитів клієнтської підтримки.
Прискорення науки та математики
Моделі GPT-5.2 Pro і Thinking визнані найкращими у світі для підтримки та прискорення наукових досліджень. Вони досягають найвищих результатів на бенчмарках науки та математики експертного рівня, таких як GPQA Diamond і FrontierMath.
Доступність
Моделі GPT-5.2 Instant, Thinking і Pro вже починають розгортатися для користувачів платних тарифних планів ChatGPT і негайно доступні через API для всіх розробників.


